Pythonの勉強がてらSpotify APIをいじっていて、アーティストの全楽曲を取得するのにちょっと苦労した。自分の知識の整理もかねて方法をメモ。
Table of Contents
0.基本と準備
Spotifyのidとalbumとtrack
Spotifyでは、アーティスト、楽曲、アルバム、プレイリストなどは全て固有のidで管理されている。ブラウザでアクセスした際の
https://………../playlist/xxxxxxxxxxxxxxxx?…..
https://…………/album/xxxxxsxxxxxxxxxx?……
のxxxxxの部分がid。
楽曲(track)を取得する際に、基本的に把握しておきたい(と思う)ポイント。
- trackはすべて”album”に属する。albumはいわゆる「アルバム」だけでなく、シングルも含む(配信シングルも収録trackひとつだけのalbumに属する)
- 複数のalbumに収録された同一曲は、それぞれ別trackとして管理される
- albumデータからはtrack情報が取れるが、trackデータから逆引きは出来ない
Spityfy APIを使う準備
Spotify APIを使うためのid取得や認証方法とかはネットに山ほど情報があるので省略。Spotifyの無料ユーザーでもAPIは使える。
以下、お約束のコード。
|
1 2 3 4 5 6 7 8 |
import spotipy from spotipy.oauth2 import SpotifyClientCredentials my_id = '................................' my_secret = '................................' ccm = SpotifyClientCredentials(my_id, my_secret) spotify = spotipy.Spotify(client_credentials_manager = ccm, language='ja') |
以下、出力例は、延べ1400曲以上らしい松田聖子(artist_id:3E5NLQpQbd0eJ18XO9zC0h)で示している。
1.アルバム/シングルから全楽曲を取得
基本的な手順は
・artist idからartist_albumsAPIでalbumのid一覧を取得
・各albumのidからalbum_tracksAPIでtrack(楽曲)データの一覧を取得
・各trackデータからタイトルを取得
となる。
アルバムから全楽曲
いわゆるアルバムから全曲名を取り出すには、まずartist_albums APIのalbum_typeにalbumを指定する。
なおalbum_typeに指定できるのは以下の4種類
- album
- single
- appears on
- compilation
(‘appears on’と’compilation’については後述)
以下、コード。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# artist_idからalbumデータを所得 results = spotify.artist_albums(id, limit=50, album_type='album') album_datas = results['items'] while results['next']: results = spotify.next(results) album_datas.extend(results['items']) print('全アルバム枚数:', len(album_datas)) # 各albumデータからtrack(楽曲)データを取得し、trackデータからtrack名(楽曲名)を取る a_trackname_list = [] # 曲名を格納 for a_data in album_datas: album_id = a_data['id'] # albumのidから各trackの情報を取得 tracks_data = spotify.album_tracks(album_id) for t_data in tracks_data['items']: a_trackname_list.append(t_data['name']) print('全アルバム収録の延べ曲数:', len(a_trackname_list)) # 同名の曲を省く a_trackname_set = set(a_trackname_list) print('全アルバム収録の総曲数:', len(a_trackname_set)) |
|
1 2 3 |
全アルバム枚数: 82 全アルバム収録の延べ曲数: 1211 全アルバム収録の総曲名数: 653 |
シングルから全楽曲
artist_albums APIのalbum_typeに’single’を指定するだけで、あとはアルバムと変わらない。
カップリング曲も含めたtrackが取得できる。
以下、両方対応のための関数を利用したパターン。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# artist_albumsの取得結果から、全album_dataを取得する def get_albumdatas_from_results(results): album_datas = results['items'] while results['next']: results = spotify.next(results) album_datas.extend(results['items']) return album_datas # 複数のalbumデータから全トラックデータを取得する def get_trackdatas_from_albumdatas(album_datas): track_datas = [] for a_data in album_datas: album_id = a_data['id'] tracks_data = spotify.album_tracks(album_id) track_datas.extend(tracks_data['items']) return track_datas results = spotify.artist_albums(id, limit=50, album_type='single') album_datas = get_albumdatas_from_results(results) track_datas = get_trackdatas_from_albumdatas(album_datas) single_tname_list = [] for td in track_datas: single_tname_list.append(td['name']) print('シングル収録の延べ曲数:', len(single_tname_list)) # 同名の曲を省く single_tname_set = set(single_tname_list) print('シングル収録の総曲数:', len(single_tname_set)) |
|
1 2 3 |
全シングル枚数: 59 シングル収録の延べ曲数: 171 シングル収録の総曲名数: 166 |
アルバム・シングルの全曲
上記で取った楽曲名を合わせるだけ。
|
1 2 3 4 5 6 |
album_single_tname_list = album_tname_list + single_tname_list print('アルバム・シングルの延べ曲数:', len(album_single_tname_list)) # 同名の曲を除外 album_single_tname_set = album_tname_set | single_tname_set print('アルバム・シングルの総曲名数:', len(album_single_tname_set)) |
|
1 2 |
アルバム・シングルの延べ曲数: 1382 アルバム・シングルの総曲名数: 706 |
2.他アーティスト作品への参加曲や各種コンピ収録曲
album_typeに’appears_on’を指定すると、アルバム・シングル以外にアーティストが参加した、他アーティスト作品(album)のデータが取れる。(英語の解説)
実際に確認した範囲では
(1)複数アーティストが参加した、いわゆるコンピ
(2)特定テーマによるベストアルバム的なもの
(3)他アーティストの作品参加
の少なくとも3種類が取れる模様。(1)の場合、albumのartist名は「ヴァリアス・アーティスト(Various artist)」になるようだ。
ともかく、このalbumには、対象アーティストが参加していないtrackも含まれている(ことが多いはず)ので、各trackのartist_idをチェックする必要がある。
以下、シンプルにtrack名を取得するコード。ハイライト部分がアルバムやシングルの処理に追加したコード。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# artist_albumsの取得結果から、全album_dataを取得する def get_albumdatas_from_results(results): album_datas = results['items'] while results['next']: results = spotify.next(results) album_datas.extend(results['items']) return album_datas results = spotify.artist_albums(id, limit=50, album_type='appears_on') album_datas = get_albumdatas_from_results(results) appears_tname_list = [] # 曲名を格納するlist for a_data in album_datas: album_id = a_data['id'] tracks_data = spotify.album_tracks(album_id) for t_item in tracks_data['items']: # 各楽曲のartist id(複数の場合あり)取得 artist_ids = [] for artist in t_item['artists']: artist_ids.append(artist['id']) # 対象アーティストのidが無ければスキップ if id not in artist_ids: continue # track名を取得 appears_tname_list.append(t_item['name']) print('appears on 延べ曲数:', len(appears_tname_list)) # 同名の曲を除外 appears_tname_set = set(appears_tname_list) print('appears on 総曲名数:', len(appears_tname_set)) |
|
1 2 |
appears_on 延べ曲数: 22 appears_on 総曲数: 17 |
3.「コンピレーション」楽曲も取得
album_typeに’compilation’を指定すると「コンピレーション」albumのデータが取れる。これは上記3種類で取れるalbumには含まれないようだ。
Spotifyで言うcompilationとは、「The Greatest Hits of xxxx」みたいな、アーティストの代表曲をまとめたものを指すらしい(英語の解説)。2.と3.で取得した以外の楽曲は取れないと思う(compilationだけ配信していれば別だが)。
ともかく、trackの取得はアルバムやシングルと同じ。
4.全楽曲を一気に取得し csv出力
artist_albums APIのalbum_type指定を省略すると、上記4種類のalbumデータ全部が取れる。
これで、2.のappears on と同じ方式で絞り込めば「全ての楽曲名」が取得できる(はず)。
|
1 2 |
延べ曲数: 1415 総曲数: 701 |
ただ、例えば同じ曲に、artist単独によるものと、他artistとのコラボとの両方がある場合、この単純な方式だと漏れてしまう。
なので、
・複数アーティスト名義(コラボなど)は楽曲名にアーティスト名を付加
さらに
・楽曲タイトルと、それぞれの収録アルバム・シングル名すべて
・楽曲を人気順に並べ替える(複数album収録曲は最も人気が高いものを採用)
・まとめたデータを最後にcsv出力
してみる。
以下、コード。artist名を取るためのartistAPIと、楽曲の人気(popularity)データを取るためのtrackAPIを新たに使っている。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 |
start_time = time.time() # データ取得時間を計測 # 全albumのデータを取得 results = spotify.artist_albums(id, limit=50) # album_type指定を省略 album_datas = results['items'] while results['next']: results = spotify.next(results) album_datas.extend(results[('items')]) print('全album数:', len(album_datas)) # 対象artistの名前 target_artist_name = spotify.artist(id)['name'] # 楽曲名をkeyにして、album_idと人気度を格納するdict trackname_datas_dic = {} #{'track_name': '...',[{'popularity':..., 'album_id:', '....'},{}...]} # album_dataを、album_idをkeyにして格納するためのdict albumid_data_dic = {} for a_data in album_datas: album_id = a_data['id'] # albumデータを格納 albumid_data_dic[album_id] = a_data tracks_data = spotify.album_tracks(album_id) # 各track情報を取得 for t_item in tracks_data['items']: # 各trackのartist_idを全て取る artist_ids = [] for artist in t_item['artists']: artist_ids.append(artist['id']) # 対象artistのidがなければスキップ if id not in artist_ids: continue # 楽曲名 track_name = t_item['name'] # 複数名義の場合は、artist名を取得し、楽曲名に付加 if len(artist_ids) > 1: artist_names = [] for a_id in artist_ids: if a_id == id: artist_names.append(target_artist_name) else: artist_names.append(spotify.artist(a_id)['name']) track_name += str(artist_names) # trackデータから人気度を取得 track_id = t_item['id'] t_data = spotify.track(track_id) popularity = t_data['popularity'] # 楽曲名のalbumごとデータを作成 data_dict = {'popularity': popularity, 'album_id': album_id } if track_name in trackname_datas_dic: trackname_datas_dic[track_name].append(data_dict) else: trackname_datas_dic[track_name] = [data_dict] print('全楽曲数:', len(trackname_datas_dic)) # 楽曲の人気順にソート # まず楽曲の収録盤ごとデータのlistを楽曲人気順に並び替え for v in trackname_datas_dic.values(): if len(v) > 1: v.sort(key=lambda x:x['popularity'], reverse=True) # 楽曲名データを最大人気順にソート trackname_datas_dic = dict(sorted(trackname_datas_dic.items(), key=lambda x:x[1][0]['popularity'], reverse=True)) # csv出力用のデータ格納 output_diclist = [] for k, v in trackname_datas_dic.items(): track_name = k popularity = v[0]['popularity'] output_dic = {} output_dic['track_name'] = track_name output_dic['popularity'] = popularity album_names = [] # trackの収録盤名を格納するlist for datas in v: album_id = datas['album_id'] album_data = albumid_data_dic[album_id] # 各アルバムの種類を取得し、付加文字列を作成 a_group = album_data['album_group'] a_type = album_data['album_type'] a_grouptype_str = '' if a_group == 'appears_on': a_grouptype_str = '参加' elif a_group == 'compilation': a_gt_a_grouptype_strstr = 'コンピ' if a_type == 'single': a_grouptype_str += 'シングル' elif a_type == 'album': a_grouptype_str += 'アルバム' elif a_type == 'compilation': if a_group == 'compilation': a_grouptype_str = 'コンピレーション' else: a_grouptype_str += 'コンピ' # アルバムタイトル album_name = album_data['name'] # csv出力用のアルバム文字列(例:参加コンピ「Spring Songs」) album_str = a_grouptype_str + '「' + album_name + '」' album_names.append(album_str) # アルバムタイトル情報を改行付き文字列に変換 album_titles_str = '\n'.join(album_names) # 出力用dictにアルバムタイトル情報を付加 output_dic['album_titles'] = album_titles_str output_diclist.append(output_dic) # csv出力 filename = '3E5NLQpQbd0eJ18XO9zC0h_all_track.csv' with open(filename, 'w', encoding='utf8', newline='') as f: writer = csv.DictWriter(f, fieldnames=['track_name', 'popularity', 'album_titles'], quoting=csv.QUOTE_NONNUMERIC) writer.writerow({'track_name': '曲名', 'popularity': '人気', 'album_titles': '収録盤'}) writer.writerows(output_diclist) print('elapsed sec:', time.time() - start_time, '秒') |
|
1 2 3 |
全album数: 161 全楽曲数: 702 elapsed sec: 135.2936475276947 秒 |
単純に曲名でリストアップした場合に比べて、楽曲名がひとつ増えている。(同名の曲で、単独名義のものと、本人含む複数名義のものがあった)。
出力したcsvはこんな感じ(一部、2022年2月中旬取得分)。
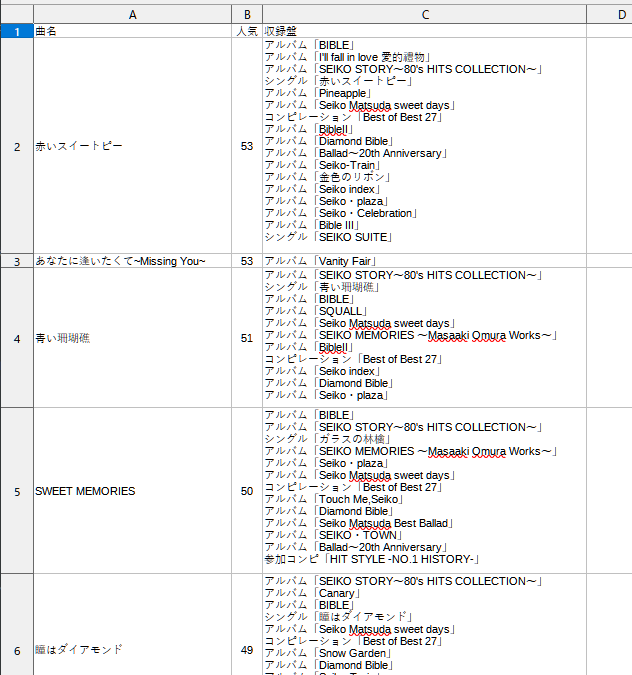
なおalbumデータ内のalbum_typeは、artist_album APIで指定したalbum_typeとは一致しないので注意が必要。API指定のalbum_typeに対応するのはalbum_groupの方になっている。ややこしい。
また、上記の複数artistの確認部分で、少々まだるっこしい処理になっているのは、API利用回数を少しでも減らすため。短時間で大量にAPIを呼び出すと制限に引っかかる(公式の英語解説)。実際に試行錯誤する際には、取得データを適宜、データ保存して、それを呼び出すようにした方がいいようだ。
以上、Python ver3.10.2で確認。
