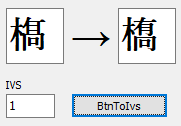
Unicode文字列から「1文字ずつ」を取り出す場合、異体字セレクタやサロゲートペアを考慮に入れる必要がある。
以下、日本語環境での話(モンゴル文字の異体字セレクタ等は未対応)。
1.std::wstring(2バイト環境)の場合
以前の記事で書いたとおり、異体字セレクタは文字の末尾に4byte分の情報が付加される。(C++Builderで異体字セレクタを使う)
このため、wchar_tが2byteの場合、wstringの「1文字」が取り得るバイト数は以下の4通りになる。
| 「1文字」の4パターン | バイト数 |
|---|---|
| 基本文字(基本多言語面) | 2byte |
| サロゲートペア | 4byte |
| 基本文字の異体字セレクタ付 | 6byte |
| サロゲートペアの異体字セレクタ付 | 8byte |
以下、文字列から、1文字ずつをstd::vectorに格納するメソッド。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
std::vector<std::wstring> create_wstring_vec( const std::wstring& wstr )const { std::vector<std::wstring> ret_wstrings; for( size_t i = 0; i < wstr.length(); ++i ) { const unsigned long c = static_cast<unsigned long>( wstr[i] ); // 異体字セレクタの判定: if( c == 0xDB40 // IVSの上位バイト: && ( i + 1 ) < wstr.length() && ( 0xDD00 <= wstr[i+1] && wstr[i+1] <= 0xDDEF ) && !ret_wstrings.empty() ) { // 直前に格納された文字に異体字情報を追加: ret_wstrings[ret_wstrings.size()-1] += wstr.substr( i, 2 ); ++i; } // サロゲートペアの判定 else if( 0xD800 <= c && c <= 0xDBFF ) { std::wstring ws = wstr.substr( i, 2 ); ret_wstrings.push_back( ws ); ++i; } // その他 else { std::wstring ws = wstr.substr( i, 1 ); ret_wstrings.push_back( ws ); } } return ret_wstrings; } |
(wchar_tが16bit/unsignedであることを前提にしたコード)
2.std::string(utf-8)の場合
utf-8文字列をstd::stringに突っ込んで使う場合もあるので(自分自身はやらないが)、ちょっと調べた。 以下のような方法で取り出せる(たぶん)。
utf-8文字は、先頭バイトを見ると1文字分のバイト数が分かるので、サロゲートペア判定は特に必要ない。 だが、そこで取れるバイト数には異体字セレクタ情報は反映されないので、自前で処理する必要がある。
文字に付加される異体字セレクタは計4byte分で、漢字用のIVSでは以下の範囲を取るようだ。
| バイト順 | 値の範囲 |
|---|---|
| 1 | 0xF3 (固定) |
| 2 | 0xA0 (固定) |
| 3 | 0x84~0x87 |
| 4 | 0x80~0xBF (0x80~0xAF) |
4バイト目は、3バイト目が0x87の時に限り最大で0xAF(たぶん)。
以下、utf-8文字列の格納されたstd::stringから1文字ずつ取り出すメソッド。
なお、IVS最初の0xF3は、単体でも1byteで文字を表現するので、まず2byte分を判定する必要がある。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
std::vector<std::string> create_u8string_vec( const std::string& utf8str )const { using uchar = unsigned char; std::vector<std::string> ret_strings; for( size_t i = 0; i < utf8str.length(); ++i ) { // 先頭バイト uchar c( utf8str[i] ); // 異体字セレクタ判定 // ------------------- // まず2byte分調べる if( c == 0xF3 && i && ( i + 3 ) < utf8str.length() && static_cast<uchar>( utf8str[i+1] ) == 0xA0 ) { // 残る2byteを調べる uchar c1 = static_cast<uchar>( utf8str[i+2] ); uchar c2 = static_cast<uchar>( utf8str[i+3] ); // 3番目の値が0x84~0x86で且つ4番目の値が0x80~0xBF // または // 3番目の値が0x87で且つ4番目の値が0x80~0xAF if( 0x84 <= c1 && 0x80 <= c2 && ( ( c1 <= 0x86 && c2 <= 0xBF ) || ( c1 == 0x87 && c2 <= 0xAF ) ) ) { // 直前に格納された文字に異体字情報を追加: ret_strings[ret_strings.size()-1] += utf8str.substr( i, 4 ); i += 3; } } // それ以外ならバイト数を求めて格納 else { unsigned int byte_count = 0; if( 0x00 <= c && c <= 0x7F ) byte_count = 1; else if( 0xC0 <= c && c <= 0xDF ) byte_count = 2; else if( 0xE0 <= c && c <= 0xEF ) byte_count = 3; else if( 0xF0 <= c && c <= 0xF7 ) byte_count = 4; else if( 0xF8 <= c && c <= 0xFB ) byte_count = 5; else if( 0xFC <= c && c <= 0xFD ) byte_count = 6; if( byte_count ) { ret_strings.push_back( utf8str.substr( i, byte_count ) ); i += byte_count - 1; } } } return ret_strings; } |
3.サンプルプログラム
C++Builderによるサンプルプログラム。
TFormにTEditとTMemoをひとつずつ、TButtonを2つ貼り付ける。
TEditとTMemoのフォントは游明朝、サイズを40にしておく。 TEditに以下の文字列を入れておく。

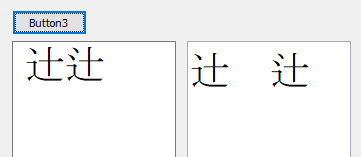
文字列の漢字部分は、最初の「辻」から順に
・基本文字
・異体字セレクタ
・基本文字
・サロゲートペア
・サロゲートペア
・サロゲートペアの異体字セレクタ付
英字は小文字のaが全角、大文字のAは半角。
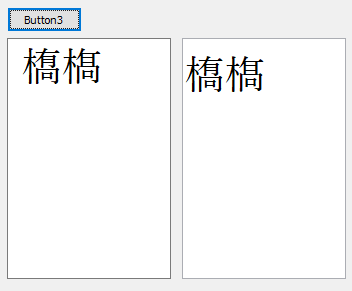
3-1.std::wstringを使った例
Button1Clickを次のように実装。
|
1 2 3 4 5 6 7 8 9 |
void __fastcall TForm1::Button1Click(TObject *Sender) { const std::wstring wstr = Edit->Text.c_str(); std::vector<std::wstring> wstring_vec = create_wstring_vec( wstr ); for( const auto& s : wstring_vec ) { Memo->Lines->Add( s.c_str() ); } } |
結果:

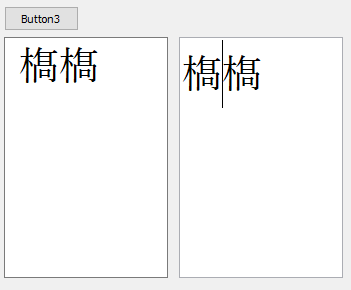
3-2.std::stringを使った例
C++BuilderにはUTF8String型があるので、変換にはそれを使っている。
Button2Clickを以下のように実装。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
void __fastcall TForm1::Button2Click(TObject *Sender) { UTF8String U8Str = Edit->Text; const std::string u8str = U8Str.c_str(); std::vector<std::string> string_vec = create_u8string_vec( u8str ); for( const auto& s : string_vec ) { UTF8String U8Str = s.c_str(); Memo->Lines->Add( U8Str ); } } |
結果:

以上、とりあえずのテストでは上手くいっているが、何か見落とし等があるかも。